クラウドリフトで見落としやすい「OSの中身」の落とし穴
クラウドリフトでは、既存サーバをAMI化し、そこからEC2を作成することがあります。
オンプレミスのサーバ更改でいえば、既存環境を複製して、新しい環境で起動するようなイメージです。
一見すると、とても便利です。
OS、ミドルウェア、設定ファイル、アプリケーション、ディレクトリ構成などを、元の環境に近い状態で再現できます。
そのため、クラウド移行では、
AMIを作って、そこからEC2を起動すればよい
と思いがちです。
しかし、ここに落とし穴があります。
EC2は起動できる。
EBSボリュームも作成できる。
別のEC2へアタッチもできる。
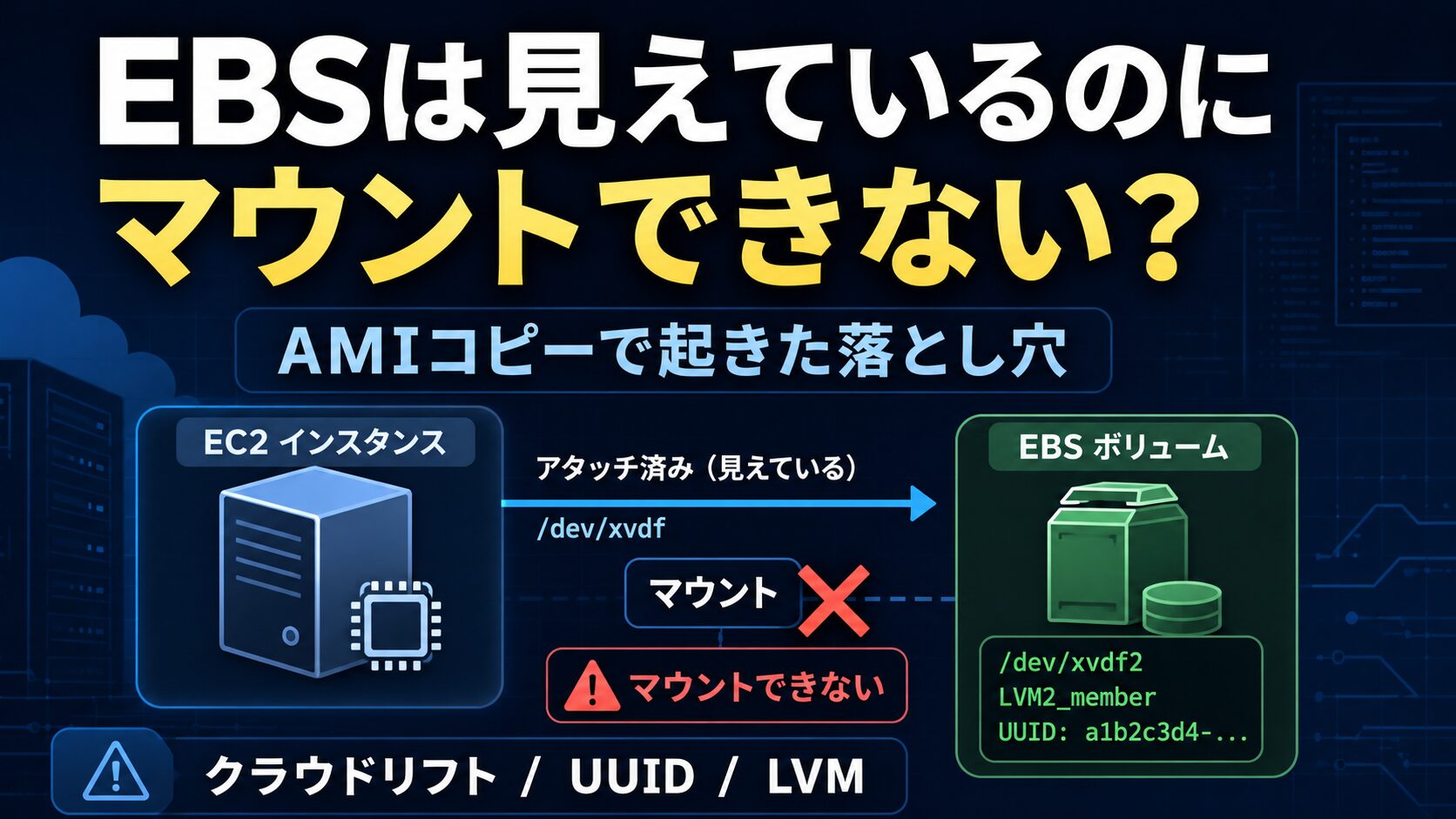
それなのに、OS上で期待どおりにマウントできないことがあります。
今回扱うのは、AMIコピーやスナップショットから復元したEBSを、既存EC2にアタッチしてデータ復旧しようとしたときに起きたトラブルです。
何が起きたのか
過去のAMIバックアップからデータを復旧したい場面がありました。
やろうとしたことは、よくある復旧作業です。
過去のAMIまたはスナップショットからEBSを復元する
復元したEBSを既存のEC2にアタッチする
OS上でマウントする
必要なファイルを取り出す
クラウド環境では、障害調査や復旧作業でよく出てくる手順です。
EBSはAWS上では問題なく作成できました。
既存EC2へのアタッチもできました。
OS上でもディスクとして見えていました。
ところが、いざマウントしようとすると失敗しました。
たとえば、以下のようにデバイスを直接指定してマウントしようとします。
mount /dev/xvdf2 /mnt
すると、次のようなエラーになります。
mount: /mnt: unknown filesystem type 'LVM2_member'
ここが今回のポイントです。
OSから見ると、/dev/xvdf2 はそのままマウントできるXFSやext系のファイルシステムではありませんでした。
LVM2_member として認識されています。
つまり、直接マウントしようとしていた対象は、ファイルシステムそのものではなく、LVMの物理ボリュームとして扱われる領域だったということです。
原因は「EBSが壊れていた」ではない
この手のエラーを見ると、最初はこう考えがちです。
EBSの復元に失敗したのではないか。
スナップショットが壊れているのではないか。
デバイス名を間違えたのではないか。
もちろん、それらも確認すべきです。
しかし今回の本質は、EBSそのものが壊れていたことではありません。
原因は二つあります。
一つ目は、直接マウントしようとした対象が LVM2_member だったことです。
二つ目は、同じAMIを元にしたインスタンス同士で、ディスクやボリューム管理情報の識別子が競合したことです。
AMIからEC2を作ると、OSの中身も含めて複製されます。
ファイルシステムのUUID、LVMのボリューム情報、/etc/fstab の記述、デバイス構成の前提なども、元の環境を引き継ぎます。
そのため、同じAMIを元にしたEC2に、同じ系統のAMIやスナップショットから復元したEBSをアタッチすると、OSから見た識別情報が競合することがあります。
作業者としては、
復元したEBSを別EC2に付けて、中身を見たいだけ
です。
しかしOS側から見ると、同じような識別情報を持つボリュームが複数見えている状態になります。
AWS上ではEBSがアタッチできていても、OS上で安全にマウントできるとは限りません。
ここを取り違えると、復旧作業で詰まります。
これはAWSの不具合というより、Linuxのディスク管理、UUID、LVM、fstab の仕組みに基づく動作です。
EBSはクラウド上のブロックストレージですが、最終的にそれをどう認識し、どうマウントするかはOS側の話になります。
なぜ LVM2_member になるのか
Linuxでは、ディスク上に直接ファイルシステムが作られている場合もあれば、LVMを使ってボリューム管理している場合もあります。
単純な構成であれば、パーティションにXFSなどのファイルシステムがあり、そのパーティションを直接マウントできます。
一方、LVMを使っている場合、物理ディスクやパーティションは、まずLVMの物理ボリュームとして扱われます。
その上にボリュームグループがあり、さらに論理ボリュームが作られ、その論理ボリューム上にファイルシステムがあります。
つまり、LVM構成では、次のような階層になります。

この場合、LVMの物理ボリュームを直接 mount しても、ファイルシステムとして認識できません。
そのため、
unknown filesystem type 'LVM2_member'
となります。
これは、OSが対象を見失っているというより、
そこは直接マウントする場所ではない
という意味に近いです。
たとえば、blkid で見ると、対象パーティションが次のように見えることがあります。
blkid /dev/xvdf2
/dev/xvdf2: UUID="xxxxx" TYPE="LVM2_member"
この状態で /dev/xvdf2 を直接 mount しても、XFSやext系のファイルシステムとしては扱えません。
UUIDの競合も見落としやすい
もう一つ重要なのがUUIDです。
Linuxでは、ディスクやパーティションを /dev/xvdf、/dev/xvdf1、/dev/nvme1n1p1 のようなデバイス名で扱うことがあります。
しかし、クラウド環境ではデバイス名だけを信じると危険です。
AWSコンソール上で指定したデバイス名と、OS上で見えるデバイス名が直感どおり一致しないことがあります。
さらに、AMIやスナップショットから復元したボリュームでは、ファイルシステムUUIDやLVM関連の識別情報が元の環境と同じまま残ることがあります。
そのため、同じAMI由来のボリュームを同じ系統のEC2にアタッチすると、UUIDやボリューム管理情報が競合し、どのボリュームをマウントすべきかが分かりにくくなります。
ここで必要なのは、勘でデバイス名を指定することではありません。
OSが実際にどう認識しているかを確認することです。
たとえば、以下のようなコマンドで確認します。
lsblk
blkid
ls -l /dev/disk/by-uuid
これらを使って、次の情報を確認します。
どのデバイスが追加ボリュームなのか
どのパーティションにファイルシステムがあるのか
LVM2_member として見えているのか
どのUUIDがどのデバイスに対応しているのか
既存ボリュームと識別情報が競合していないか
どう対処したのか
今回の対処の核心は、同じAMI由来ではない作業用EC2を用意し、そこに復元EBSをアタッチしてマウントするという点です。
狙いは、同じAMI由来のOSボリュームと復元ボリュームを同じEC2上に同居させることで起きる、UUIDやLVM関連の識別情報の競合を避けることです。
ここでいう「別のEC2を用意する」とは、LVM2_member が自動的にマウントできるようになる、という意味ではありません。
そのうえで、OS上で lsblk、blkid、/dev/disk/by-uuid を確認し、どの領域が直接マウントできるファイルシステムなのか、どの領域が LVM2_member なのかを切り分けました。
LVM構成を維持したまま確認したい場合は、pvscan、vgscan、vgchange -ay でボリュームグループを有効化する方法や、複製されたLVMボリュームを別物として扱う vgimportclone を使う方法もあります。
また、既存EC2上で対応せざるを得ない場合は、mount -o nouuid で一時的に参照する方法もあります。
ただし、これらは環境と目的によって適否が分かれます。
今回は復旧対象のファイルを一時的に安全に取り出すことが目的だったため、作業用EC2を用意し、UUIDで対処する方針を採りました。
具体的な手順は以下のとおりです。
まず、/dev/disk/by-uuid でUUIDとデバイスの対応を確認します。
ls -l /dev/disk/by-uuid
たとえば、以下のように表示されます。
lrwxrwxrwx. 1 root root 11 Feb 16 07:47 1c5999b9-594d-40aa-84d2-167a92a977c5 -> ../../xvdf1
lrwxrwxrwx. 1 root root 11 Feb 16 07:46 949779ce-46aa-434e-8eb0-852514a5d69e -> ../../xvda2
この例では、xvdf1 がアタッチした復元ボリューム、xvda2 が既存のルートボリュームとして見えています。
次に、/etc/fstab にマウント先を追記します。
# fstab.new(変更後)
UUID=949779ce-46aa-434e-8eb0-852514a5d69e / xfs defaults 0 0
UUID=1c5999b9-594d-40aa-84d2-167a92a977c5 /mnt xfs defaults 1 1
そのうえで、マウントを実行します。
mount -a
最後に、マウント先の中身を確認して、意図したボリュームであることを確認します。
cat /mnt/etc/hostname
この確認により、単にマウントできたかどうかだけでなく、本当に目的のボリュームを参照できているかを確認できます。
クラウドリフトでは「コピーできた」と「運用できる」は違う
クラウドリフトでよくある誤解があります。
AMIを作れた。
EC2が起動した。
EBSもアタッチできた。
だから移行できている。
もちろん、これらは重要です。
しかし、それだけでは十分ではありません。
本当に確認すべきなのは、移行後に必要な運用作業ができるかです。
たとえば、障害時に旧ボリュームを別EC2にアタッチして中身を確認できるか。
/etc/fstab の記述は移行後の構成に合っているか。
デバイス名だけに依存せず、UUIDで対象を識別できるか。
LVM構成なら、LVMとして認識・有効化できるか。
こうした確認が抜けると、本番障害時に困ります。
通常時は問題なく動いているように見えても、いざ障害調査や復旧作業をしようとしたときに、
そのボリューム、どうやって安全にマウントするんだっけ?
となります。
クラウドリフトでは、このような運用時の確認観点が後回しになりがちです。
事前にどうチェックすべきだったのか
チェックリストとして最小限に絞るなら、見るべきポイントは次の4つです。
1. OSのディスク構成を確認する
ルートボリュームはどれか。
追加ボリュームはどれか。
パーティション構成はどうなっているか。
ファイルシステムは何か。
LVMを使っているか。
UUIDは何か。
/etc/fstab はどう書かれているか。
クラウドリフトでは、EC2を起動できるかだけでなく、移行後のOS内部構成まで確認する必要があります。
2. LVM構成か、直接マウント可能なファイルシステムかを確認する
lsblk や blkid で、対象がXFSなどのファイルシステムなのか、LVM2_member なのかを確認します。
LVM2_member であれば、直接 mount する対象ではありません。
LVMとして認識させるのか、UUIDでマウント対象を指定するのかを、OS構成に応じて判断する必要があります。
3. UUIDの対応を確認する
/dev/disk/by-uuid を確認し、どのUUIDがどのデバイスを指しているかを確認します。
同じAMI由来のボリュームを扱う場合は、UUIDやボリューム管理情報の競合に注意します。
デバイス名だけで判断せず、UUID、ファイルシステム、マウント先の対応を確認します。
4. 復旧手順として事前に試す
設計書や手順書に「EBSをアタッチしてマウントする」と書いてあっても、本当にできるとは限りません。
別EC2にEBSをアタッチする。
OS上でデバイスを確認する。
UUIDを確認する。
必要に応じてLVM構成を確認する。
マウントして中身を確認する。
作業後にアンマウントする。
ここまで一度試しておくべきです。
復旧手順は、障害が起きてから初めて実行するものではありません。
これは詳細設計・運用設計の問題である
今回の話は、EBSをマウントできなかったという作業トラブルに見えます。
しかし、本質は詳細設計・運用設計の問題です。
クラウドリフトでAMIやEBSを扱うなら、設計時点で少なくとも以下を決めておく必要があります。
移行後のEBS構成
OS上のデバイス認識
LVMを使っているかどうか
ルートボリュームと追加ボリュームの識別方法
UUIDの確認方法
/etc/fstab の記述方針
障害時に別EC2へアタッチして確認する手順
マウント確認後に何を見て正常と判断するか
これらは、運用当日に作業者が感覚で判断するものではありません。
設計書、運用設計書、作業手順書、復旧手順書に落としておくべき内容です。
特に、構築担当者と運用担当者が分かれているプロジェクトでは、この問題が起きやすくなります。
構築担当者は、「AMIからEC2は起動した」「EBSも作成できた」と考える。
一方、運用担当者は障害時に、「復元したEBSをどのEC2にアタッチし、どのUUIDを見て、どのディレクトリにマウントし、何を確認すればよいのか」で迷う。
この間を埋めるのが、詳細設計と運用設計です。
「EC2が起動した」ことと、「運用できる」ことは違います。
「EBSがアタッチされた」ことと、「安全にマウントできる」ことも違います。
この違いを設計で潰しておくことが重要です。
まとめ
AMIコピーやスナップショット復元で作成したEBSは、AWS上でアタッチできていても、OS上でそのまま期待どおりにマウントできるとは限りません。
今回の事象では、直接マウントしようとした対象が LVM2_member であり、さらに同じAMI由来のボリューム識別情報が競合していたことが問題でした。
対処の核心は、同じAMI由来ではない作業用EC2を用意して、そこに復元EBSをアタッチすることです。
そのうえで、/dev/disk/by-uuid を確認し、実際にマウント対象となるファイルシステムのUUIDを指定してマウントしました。
作業前には、lsblk、blkid、/dev/disk/by-uuid で、OSが対象ボリュームをどう認識しているかを必ず確認します。
デバイス名だけで判断せず、UUID、ファイルシステム、マウント先の対応を確認してから作業に入ることが重要です。
クラウドリフトで本当に大事なのは、サーバをクラウド上で起動することだけではありません。
移行後に、調査できること。
復旧できること。
運用できること。
ここまで確認して初めて、クラウドリフトは現場で使えるものになります。
関連記事
この考え方については、以下の記事でも整理しています。
【前編】詳細設計で決めること|基本設計を「構築・テスト・運用できる形」に落とし込む工程
シリーズ全体は「実務で使えるシステム開発方法論」マガジンにまとめています。


コメント