
企業のDX化は加速の一途を辿り、コンピューターシステムの重要性が一層増す中、ひとたびシステム障害を起こせば、システムを提供する企業は社会的信頼およびブランド失墜のリスクを抱えることになります。みずほ銀行やKDDIのシステム障害は記憶に新しいことでしょう。
各システムでは、いかにシステム障害の発生を予防し、発生時の影響を最小限に抑えるかが重要な課題の一つとなっています。その解決手段として登場するのが「システム監視」です。「システム監視」を行わなければ、システムに障害が発生しても気づくことができず、利用者から「システムが使えない」と問い合わせやクレームが来てから障害に気づくことになります。
つまり、システム監視とは「次の2点を事前に確認し、必要に応じて関係者へ通知を行う仕組み」と言えます。
- システムが正常に稼働しているか
- システムに障害予兆となる兆候はないか
一方、運用/保守性の要件にあわせたシステム監視を行うには複数種類の監視方法があり、複雑に組み合わせながら構築することになります。今回は、システム開発で必ず必要となるシステム監視の基本的なシステム構成と様々な監視方法について解説したいと思います。
システム監視が定義される非機能要件「運用/保守性」をやさしく解説!もあわせて参照ください。
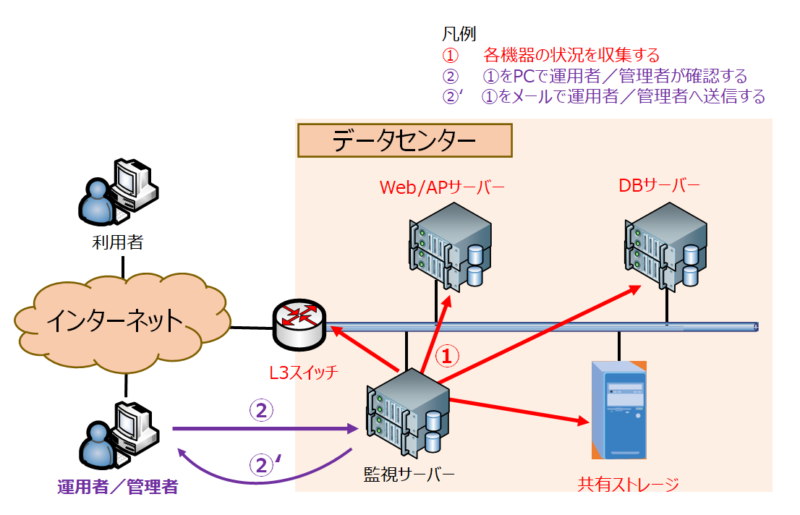
システム監視の基本的なシステム構成
一般的なシステム監視のシステム構成イメージを以下に示します。
システム監視では、監視する側、監視される側といった役割が発生します。
監視する側が「監視サーバー」、監視される側の機器を「監視対象機器(Web/APサーバなど)」とよびます。
多くの場合、「監視サーバー」は下記のような監視情報を収集※し、運用者/管理者がパソコン画面で確認し、メールでも監視情報を受信するといったシステム監視を行っています。
※システム監視で収集する情報の例
- Web/APサーバーと通信状況
- DBサーバーのCPU負荷状況
- 共有ストレージのディスク容量
- 機器それぞれのログに怪しいメッセージ出力がないか
念のため補足すると、クラウドサービスではシステム監視に対する考え方が若干違うので注意が必要です。
例えば、AWSには各種リソースを監視してくれるフルマネージドの運用監視サービス「CloudWatch」があり、監視サーバーといった考えはありません。当然ですが、機器といった概念のないマネージドサービスの監視も対応しています。従来のシステム構成で行うシステム監視とは概念的に異なります。
一方、システム監視に対する基本的な考え方が、クラウドやAWSだからといって変わることはありません。基本的には同様の考え方で通用します。マニュアル車が運転できる人はオートマチック車も運転できるのと同じようなものです。
余談ですが、その逆は難しいようです。
徐々にクラウドしか知らないクラウドネイティブのエンジニアも増えてきました。しかし、オンプレとクラウドが混在する過渡期の今、まだまだオンプレミスにおける知見がないと業務をスムーズに進められないケースがあります。具体的には、オンプレでの設計思想を理解できず、クラウド上にリファクタリングできないケースです。クラウドネイティブが悪いわけではありませんが、システム開発の目的は「お客様とコミットしたQCDを守ること」であり、「クラウド機能による開発」ではないことを忘れてはいけません。クラウド利用は、目的達成の手段でしかありません。
システム監視の監視方法
監視サーバーが、監視対象機器の「何」に対して「どのように」監視するかの処理方式が監視方法です。
監視方法の考え方は複数種類に渡ります。そして、その複数種類を組み合わせてシステム監視を実現します。さまざまな監視方法が用意されているのは、あらゆるシステム障害、状況に対して検知、通知しなければならないことの裏返しでもあります。システムの安定運用、障害発生の未然防止はシステム監視の品質にかかっているからです。
以下に示すのは、代表的な監視方法の例です。最低限、押さえておきましょう。
それぞれの監視方法の詳細は表中のリンクを参考にしてください。
| 監視方法 | 内容 |
| 死活監視 | 監視サーバーより、pingなどでサーバ、ストレージ、ネットワーク機器が起動しているかを監視する。 |
| エージェント監視 | 監視対象機器に監視用ソフトウェア(以下、エージェントとよぶ)を導入し、エージェントが監視対象サーバー自身を監視する。怪しいメッセージ出力がログにあれば監視サーバーに通知する。 |
| エージェントレス監視 | 監視対象機器にエージェント導入をせず、監視サーバーにてリモートで監視対象機器を監視する。エージェント監視に比べて監視できることが限定される場合が多い |
リソース稼働情報監視 | リソース(CPU、メモリ、ディスクI/Oなど)稼働情報を収集するエージェントによって、パフォーマンス低下の予兆を監視し、パフォーマンスチューニング向けレポート出力など行う。 |
| 個別ソフトウェアに特化した監視(エージェント監視の一部) | Oracle、SQL Serverといった個別ソフトウェアのリソース稼働情報のチェックに特化した専用製品で監視する。OS標準コマンドでは検知できない詳細が監視可能 製品例:JP1/Performance Management – Agent Option for Oracle、JP1/Performance Management – Agent Option for Microsoft® SQL Server |
例えば、監視対象であるDBサーバーが起動しているのかどうかを監視したい場合は「死活監視」を行います。
なぜ「死活監視」が選択されるのかを補足しておきます。
誤解を恐れずに言えば、IT業界では「死活監視」=「ping(ICMP Echo Reply)実行結果で判断」とする事が多いからです。もちろん他の方法、例えばsnmpを利用しても死活監視は可能です。このあたりを理解するには、ネットワークプロトコル、アクセス制御の知識が必要になるので詳細説明は割愛しますが、基本の理解としては、表の内容を抑えておけば十分です。
まとめ
システム監視は、システムの正常性確認と予防保守の観点で導入され、必要に応じて監視情報を関係者へ通知する仕組みです。
システム毎に検知、通知しないければならな情報は異なるため、システム要件に応じた適切な監視方法の選択が必要です。検知、通知精度が低いと、重大なシステム障害や予兆を見落とす可能性につながります。まずは、システム監視の必要性と基本を理解しましょう。


コメント