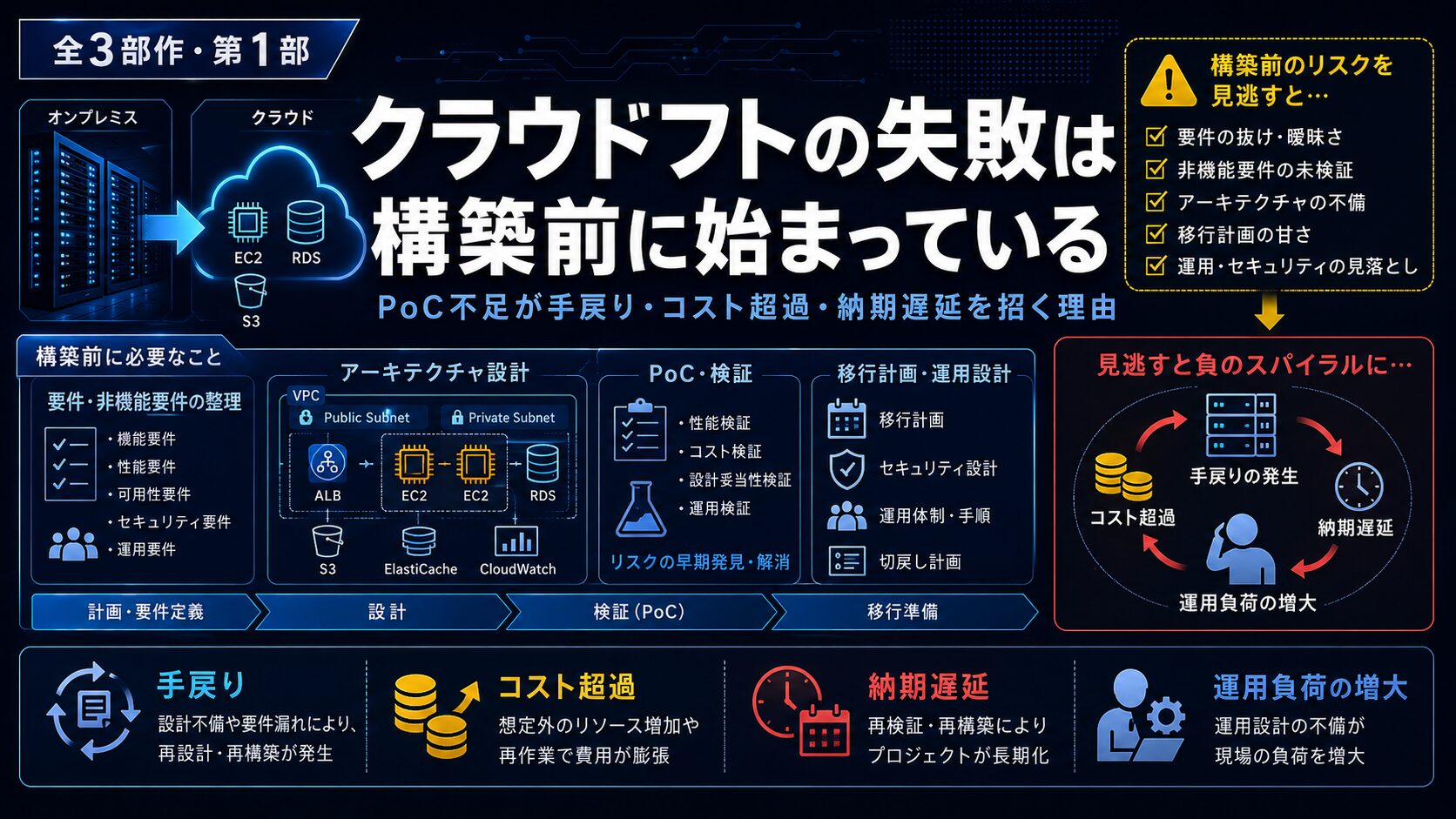
「AWSに移行したのに、なぜか現場が疲弊している」「構築フェーズに入ってから、想定外のトラブルが続き、スケジュールが削られていく」
クラウドリフトでは、こうしたことが実際に起こります。
性能が出ない。別AZでEC2を起動したのに、OS内のルート情報が原因で通信できない。Auto ScalingでEC2は再作成されたのに、監視やジョブ実行対象として認識されない。EFSで共有ファイルを読み書きできたのに、複数サーバからのファイル更新や差し替えで想定外の挙動が出る。
こうしたトラブルは、現場では「個別の設定ミス」や「確認不足」として見えます。
しかしプロジェクト全体で見ると、別の姿が見えてきます。
クラウドリフトの失敗は、構築前に始まっている。
トラブルが表面化するのは、EC2にログインできなくなった時、RDSの制約に気づいた時、性能試験で想定したスループットが出なかった時です。
しかし実際には、もっと前から始まっていることが多いです。PoCで確認すべきことを確認しないまま基本設計へ進む。クラウド上で成立するか分からない処理方式を、オンプレ時代の感覚で決める。AWSサービスの仕様、制約、課金体系、運用モデルを十分に確認しないまま、構築と試験へ進む。
その結果、後工程で問題が表面化します。
※この記事は、クラウドリフトPoCについて整理する全3部作の第1部です。
これまでの記事では、クラウドリフトが必要になる背景や、クラウド移行で起きやすい個別トラブルを扱ってきました。今回からは、その個別トラブルを「PoCで事前に潰すべき設計リスク」として整理していきます。
- 第1部:技術トラブルがなぜ手戻り・コスト超過・納期遅延につながるのか、その「失敗の構造」を整理します
- 第2部:PoCで見るべき10の設計リスクを整理します
- 第3部:PoC結果を設計・試験・運用・見積へどう反映するかを整理します
この記事で分かること
クラウドリフトで発生するトラブルを、単なる個別事象としてではなく、PoC不足によって残った設計リスクとして整理します。ポイントは次の3つです。
- クラウドリフトのトラブルは、構築中に突然始まるわけではない
- 多くの場合、構築前に確認すべき設計リスクが残っている
- PoCは「試しに動かすこと」ではなく、後工程の手戻りを防ぐための設計判断材料である
なぜクラウドリフトの失敗が「構築前」に始まっているのかを、以下で説明します。
クラウドリフトのトラブルは「個別事象」に見える
クラウドリフトでは、さまざまなトラブルが発生します。
たとえば、これまでの記事でも以下のようなテーマを扱ってきました。
- アクセス・起動:AMIから起動したEC2でSSHログインできない
- AZ障害・復旧:別AZで起動したWindowsが、OS内のルート情報により通信できない
- 可用性:Auto ScalingでEC2は再作成されたが、業務復旧まで到達しない
- 運用・ログ:CloudWatch LogsのS3エクスポートが想定通り動かない
- バックアップ:AWS Backupの「5日保存」を「5営業日保存」と誤解する
- ストレージ:EBSは容量拡張は比較的容易だが、縮小には再作成とデータ移行が必要になる。EFS/EBSの使い分けで性能・復旧方式が変わる
- データベース:RDS for Oracleの制約により、オンプレOracleと同じ運用ができない
- 運用・共通:ジョブ管理や監視方式をクラウド移行後に見直す必要が出る
- ライセンス:Microsoft製品や商用製品は、技術的に動いても、AWS上での利用がライセンスやサポート条件上認められない場合がある
- クラウド責任分界:クラウドがストレージ障害を吸収しても、IaaS/SaaS境界の外側にあるOS領域は利用者側の責任。ログ肥大化によるOS領域枯渇が盲点になる
こうしたトラブルを一つひとつ見ると、個別の設定ミスや確認不足に見えます。
SSHの設定ミス。
OS内部のルート情報の見落とし。
cloud-init の理解不足。
バックアップ保持期間の確認不足。
ストレージ方式の選定ミス。
監視設計の漏れ。
ライセンス確認の遅れ。
もちろん、それぞれの直接原因はあります。
しかし、クラウドリフト案件として見た場合、これらを単なる個別ミスとして片付けてはいけません。
なぜなら、こうした問題の多くは、構築中に突然発生したのではなく、もっと前の段階で確認すべきことを確認しないまま進んだ結果だからです。
問題の本質はここにあります。
クラウドリフトで発生する個別トラブルの多くは、PoC不足による設計リスクの未解消として説明できる。
個別トラブルに見えるものの正体
クラウドリフトの怖さは、トラブルが発生した瞬間ではありません。
本当に怖いのは、その時点ではすでに設計、構築、試験、運用設計、見積、スケジュールが進んでおり、手戻りが大きくなっていることです。
たとえば、構築フェーズで以下のような問題が分かったとします。
- この運用はAWSではそのままできない
- このミドルウェアはAmazon Linuxでは動かない
- RDS for Oracleでは、オンプレOracleと同じチューニングができない
- EFSの性能では、業務処理のレイテンシ要件を満たせない
- 既存のジョブ管理製品をそのまま使うと、クラウド環境での運用に合わない
- サーバー上のExcel帳票生成が、ライセンスやサポート上の理由でそのまま使えない
この時点で設計を変えようとすると、影響はかなり大きくなります。
設計書を直すだけでは済みません。
構築手順も変わります。
パラメータシートも変わります。
試験項目も変わります。
運用手順も変わります。
顧客説明も必要になります。
場合によっては、見積とスケジュールも変わります。
これがクラウドリフトの手戻りです。
単なる技術トラブルではありません。
プロジェクト全体のQCDを崩す問題になります。
クラウドリフトで崩れるのは技術ではなくQCD
クラウドリフトで発生する問題は、最初は技術課題として見えます。
ログインできない。
通信できない。
性能が出ない。
バックアップが想定通りに戻せない。
監視がうまく飛ばない。
ライセンスが使えない。
しかし、プロジェクトとして見ると、それは技術課題だけでは終わりません。
実際には、次のような形でQCD全体に波及します。
- コスト超過
- スケジュール遅延
- 品質劣化
- 設計手戻り
- 試験やり直し
- 運用設計の再検討
- 顧客説明の増加
- プロジェクトメンバーの疲弊
特に危険なのは、性能、ストレージ、DB、運用方式に関する問題です。
これらは、設定値を少し変えれば解決するとは限りません。
たとえば、PoC不足により、EFSの性能が本番相当負荷で足りないと後から分かったとします。
その場合、単にスループット設定を上げれば済むかもしれません。
しかし、それでも性能目標に届かない場合は、ファイル配置や処理方式そのものを見直す必要が出ます。
EFSを使う前提だったものを、EC2+EBS構成に変える。
共有ファイルの扱いを変える。
アプリケーションの処理方式を変える。
バックアップ方式を変える。
監視項目を変える。
障害時の復旧手順を変える。
性能試験シナリオを作り直す。
ここまで来ると、もはや一部設定の見直しではありません。
基本設計からの手戻りです。
さらにPM/PLの視点で見ると、影響は技術チームの中だけでは収まりません。
基本設計を直す。
詳細設計を直す。
構築手順を直す。
試験計画を見直す。
性能試験の前提を変える。
運用手順を作り直す。
顧客へ変更理由を説明する。
追加費用とスケジュール延伸を調整する。
この連鎖が発生します。

つまり、クラウドリフトの設計漏れは、技術課題として始まり、最後はQCD課題になります。
これを構築後や試験中に初めて認識するのは、かなり危険です。
オンプレの設計思想はそのまま通用しない
クラウドリフトは、オンプレのサーバをAWS上のEC2に置き換えるだけの作業ではありません。
ここを誤解すると、設計漏れが増えます。
オンプレ環境では、比較的自由に設計できたものが多くあります。
OS設定。
ミドルウェア設定。
ストレージ構成。
ネットワーク構成。
監視方式。
ジョブ管理。
バックアップ方式。
セキュリティ設定。
HA構成。
運用スクリプト。
商用製品の導入。
ライセンス運用。
もちろん、オンプレにも制約はあります。
しかし、オンプレではサーバ、ストレージ、ネットワーク機器、ミドルウェア、運用製品を組み合わせて、プロジェクト側でかなり細かく作り込めました。
一方、AWSでは違います。
AWSサービスの仕様があります。
マネージドサービスの制約があります。
課金体系があります。
メンテナンスの考え方があります。
責任共有モデルがあります。
IAM、Security Group、CloudWatch、RDS、EFS、EBS、S3など、AWS側の設計思想があります。
つまり、プラットフォームがAWSに変わる以上、『非機能要件の実現手段』は必ず変わります。
正確には、こうです。
オンプレで暗黙的に成立していた設計を、AWSのサービス仕様、制約、課金体系、運用モデルの上で再検証する必要がある。
ここをPoCで確認せずに進めると、後から詰まります。
たとえば、オンプレではサーバが固定されている前提で、監視やジョブ管理を設計していたかもしれません。
しかし、AWSではAuto Scalingや復旧方式によって、EC2が入れ替わる前提になる場合があります。
この時、EC2が起動すれば終わりではありません。
ホスト名はどうするのか。
DNS登録はどうするのか。
監視対象への登録はどうするのか。
ジョブ実行対象としてどう認識させるのか。
ログ出力先はどうするのか。
障害時の運用手順はどう変わるのか。
ここまで確認して初めて、業務復旧と言えます。
EC2が起動しただけでは、業務復旧ではありません。
また、クラウドリフトはクラウドネイティブ化とも違います。
クラウドリフトの目的は、多くの場合、既存システムを大きく作り替えることではありません。
オンプレで動いているシステムを、できるだけ低リスク、低コスト、短期間でクラウド上に移すことです。
そのため、既存の設計思想や運用方式をある程度踏襲することになります。
しかし、ここに難しさがあります。
既存設計を踏襲したい。
でも、AWSではそのまま実現できないことがある。
マネージドサービスを使えば楽になる部分もある。
しかし、既存運用と合わない部分もある。
クラウドネイティブに寄せすぎると、アプリ改修や運用変更が増える。
オンプレ方式を無理に残すと、クラウドの良さを活かせず、コストも運用も重くなる。
このバランスを見極める必要があります。
だからPoCが重要になります。
それでもクラウドリフトは避けにくい
クラウドリフトは難しい。
しかし、避け続けることも難しいのが現実です。
政府系・公共系では、クラウド・バイ・デフォルトの流れがあります。
民間企業でも、データセンター更改、ハードウェアEOL、OS・ミドルウェア保守切れ、オンプレ運用人材の不足、災害対策、拡張性確保、初期投資抑制といった理由から、クラウド利用を検討する場面が増えています。

だからこそ、効率よく、リスクを抑えて進める必要があります。
そのために必要なのは、大きく3つです。
1つ目は、実案件の事例を収集することです。
AWS公式ドキュメントを読むことは大切ですが、それだけでは、既存運用との衝突、ライセンス制約、性能特性、バックアップの戻し方といった落とし穴は見えにくいです。実際に起きたトラブルの事例から学ぶことが重要です。
2つ目は、質の高いPoCを実施することです。
「EC2上でアプリが起動した」で終わるPoCでは、設計リスクは潰せません。本番相当の負荷、障害時の復旧、監視、ジョブ、バックアップまで含めて検証シナリオに落とし込んで初めて、基本設計の判断材料になります。
3つ目は、リフト経験者を含めたチームを作ることです。
基盤SEだけでは業務影響を判断しきれず、業務SEだけではAWSの制約やストレージ、ネットワークの設計リスクを判断しきれません。クラウド有識者、既存システム有識者、業務・アプリ担当、インフラ基盤・処理方式担当を巻き込み、PoCで分かったことを設計、試験、運用、見積へ反映する体制が必要です。
PoCは「試しに動かすこと」ではない
ここまでの話を踏まえると、PoCの意味が少し変わって見えるはずです。
PoCと聞くと、「試しに作ってみる」「動くか確認する」というイメージを持つかもしれません。
もちろん、それも間違いではありません。
しかし、クラウドリフトにおけるPoCをそれだけで捉えると危険です。
PoCで確認するのは、AWSサービスが使えるかどうかだけではありません。
既存業務の処理方式、運用方式、復旧方式、名前解決、バックアップ、監視、ジョブ、ファイル更新方式、DB運用、ライセンス、コストが、クラウド上の構成で成立するか。
そこまで確認して初めて、PoCの結果を基本設計の判断材料にできます。
たとえば、次のような確認だけでは不十分です。
- EC2でアプリケーションが起動した
- EFSでファイルを読み書きできた
- RDSに接続できた
- CloudWatch Logsにログが出た
- AWS Backupのジョブが成功した
これらは大事な確認です。
ただし、それだけでは「業務で使える」とは言えません。
オンプレ時代の検証では、プロトタイプアプリケーションを作り、主要な処理を流して、基盤上でアプリケーションが動くことを確認する、という進め方もありました。
もちろん、それ自体が無意味だったわけではありません。
サーバ、OS、ミドルウェア、ネットワーク、ストレージの基本的な組み合わせを確認するうえでは、有効な検証です。
しかし、クラウドリフトでは、それだけでは足りません。
AWS上でアプリケーションが起動することと、クラウド上の構成で業務が安定して回ることは違います。
EC2が起動しても、ホスト名、DNS登録、監視、ジョブ実行対象、ログ収集先、ミドルウェア起動まで回らなければ、業務復旧とは言えません。
EFSでファイルを読み書きできても、本番相当のファイル数、ディレクトリ構造、排他制御、ファイル差し替え、バックアップ、リストアまで成立しなければ、業務で使えるとは言えません。
CloudWatch Logsにログが出ても、運用で必要なタイミングに確認できるのか、通知すべきアラームと通知抑止すべきメッセージを整理できるのか、試験工程へ監視観点を引き継げるのかを見なければ、運用設計にはつながりません。
バックアップジョブが成功しても、必要なデータを、必要な時間内に、整合性を保って戻せるとは限りません。
つまり、PoCで見るべきなのは、「AWS上でとりあえず動くか」だけではありません。
既存の機能要件・非機能要件・運用要件を、AWS上でどの方式なら現実的に満たせるのか。
既存設計を踏襲するのか。
マネージドサービスに置き換えるのか。
商用製品を継続するのか。
代替製品に変えるのか。
クラウドネイティブなサービスに寄せるのか。
この判断をするためにPoCがあります。
では、具体的に何を判断するのでしょうか。
その構成で基本設計に進んでよいのか。
その運用方式で本番後も回せるのか。
そのサービス仕様で既存要件を満たせるのか。
そのコストでプロジェクト計画に収まるのか。
こうした設計判断に使えるPoCでなければ、後工程の手戻りを防ぐことはできません。
クラウドリフトのPoCは、単なる動作確認ではありません。
基本設計に入る前に、クラウド上で成立する処理方式、構成方式、運用方式、復旧方式、コスト感を見極めるための設計リスク潰しです。
ここが最も重要です。
たとえば、以下のような確認は、単なる動作確認ではありません。
- RDS for Oracleで、既存DBの可用性・性能要件を満たせるか
- EFSで、共有ファイルの性能要件を満たせるか
- AWS Backupで、必要な世代管理とリストア要件を満たせるか
- CloudWatch中心の監視で、既存運用を置き換えられるか
- JP1を継続するのか、ZabbixやHinemosなどに置き換えるのか
- 既存のセキュリティポリシーをAWS上のIAMやSecurity Groupへどう落とすのか
- BYOLかMarketplaceかで、ライセンス費用やサポート条件はどう変わるのか
- RHELを継続するのか、Amazon Linuxへ寄せるのか
- その場合、既存ライブラリや運用スクリプトは動くのか
- 開発環境や試験環境の利用時間増加が、クラウド利用料にどれだけ影響するのか
これらはすべて、後工程で発覚すると危険な設計リスクです。
PoCで潰すべきなのは、こういう論点です。
なぜPoCで気づけなかったのか
クラウドリフトで怖いのは、AWSの機能を知らないことだけではありません。
もっと怖いのは、クラウドリフト固有のリスクを洗い出す機会が、プロジェクト計画の中に十分に組み込まれていないことです。
しかし、実際のプロジェクトではこれが簡単ではありません。
既存システムを、AWSの仕様、制約、課金体系、運用モデルの上に再配置する。
それがクラウドリフトです。
だから、PoCが必要になります。
ただし、PoCだけですべての設計リスクを見つけられるとは限りません。
事前にシナリオを立てても、実際には想定外の問題が出ます。
重要なのは、そこで出た問題を個別対応で終わらせないことです。
なぜ見落としたのか。
どの設計リスクに分類されるのか。
次の工程へ何を引き継ぐべきか。
ここまで整理して初めて、PoCは後工程の手戻りを防ぐ材料になります。
まとめ:失敗はPoC不足から始まる
クラウドリフトでは、オンプレで暗黙的に成立していた設計前提が、AWS上でもそのまま成立するとは限りません。
PoCは「試しに動かすこと」ではありません。
後工程で致命傷になる設計リスクを、構築前に見つけるための作業です。
特に、クラウドリフトPoCでは次のような観点を、単なる確認項目ではなく「手戻りを防ぐための設計リスク」として見ておく必要があります。
- 可用性・信頼性
- 性能・キャパシティ
- ストレージ
- バックアップ
- 運用・監視
- ジョブ管理・アプリ配布
- セキュリティ・アクセス管理
- ライセンス・製品サポート
- DB・OS・ミドルウェア互換性
- コスト・キャパシティ管理
これらは、確認項目を並べれば終わるものではありません。
後工程で発覚した時に、設計、試験、運用、見積へどう波及するのかまで見ておく必要があります。
クラウドリフトの失敗は、構築前に始まっている。
この10項目については、以下の記事で前編・後編に分けて整理しています。
続く第3部では、PoCの結果を「結果報告」で終わらせず、設計・試験・運用・見積へどう渡すかを整理します。


コメント