AWSを使っていると、EC2を一時的に停止・起動したい場面があります。
たとえば、検証作業、メンテナンス、OS設定変更、ミドルウェア設定変更、不要時間帯の停止などです。
単体のEC2であれば、停止して、起動する。それだけです。
しかし、そのEC2がAuto Scaling Group配下のインスタンスだった場合、話は少し変わります。
Auto Scaling Groupは、単にEC2をまとめて管理する仕組みではありません。指定された台数を維持するために、インスタンスの状態を監視し、異常と判断した場合には新しいインスタンスに置き換える仕組みです。

ここで、現場で起こりがちな事故があります。
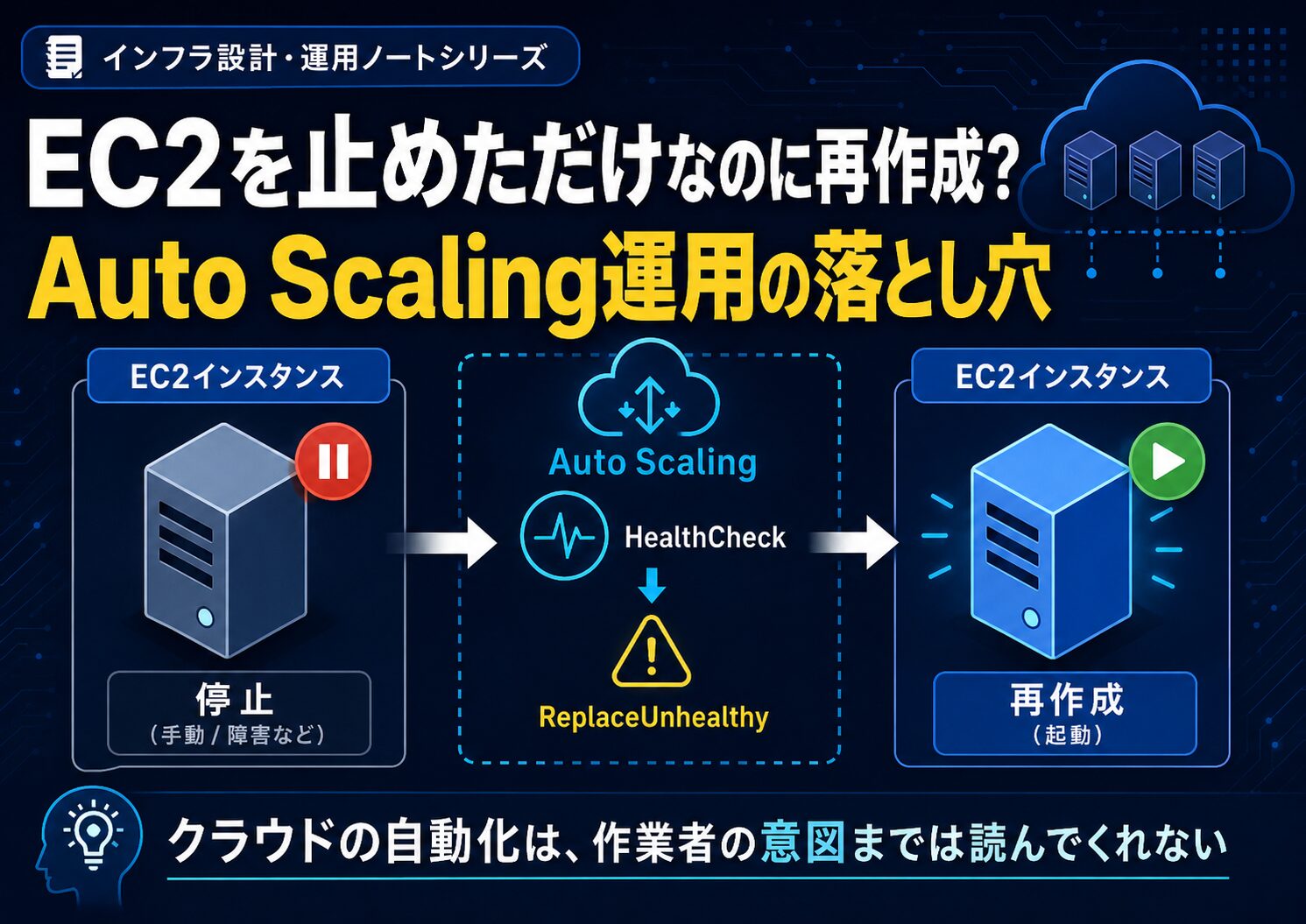
Auto Scaling対象のEC2を停止・起動したところ、意図せずインスタンスが再作成されてしまう。
作業者としては「既存のEC2を一時停止して、また起動しただけ」のつもりです。しかしAuto Scaling側から見ると「正常ではないインスタンスがいる。希望台数を維持する必要がある」という判断になることがあります。そして結果として新しいEC2が起動され、元のEC2が置き換えられてしまう。
これが、Auto Scaling配下のEC2停止・起動で起こる落とし穴です。
クラウドでも、過去の落とし穴が消えているとは限らない
実はこれ、かなり昔に経験した事象です。
Auto Scaling配下のEC2を停止・起動したところ、意図せずインスタンスが再作成されてしまった。
当時は、「そんな動きをするのか」と思いました。
ただ、クラウドサービスは日々進化します。
昔の事故事例を、今もそのまま起こる前提で語るのは危険です。
一方で、過去に起きた事故や落とし穴が、現在では完全に解消されているとも限りません。
特に、Auto Scaling、ヘルスチェック、自動復旧、フェイルオーバーのような仕組みは、クラウドサービスの基本的な設計思想に関わります。
そのため、昔の事例であっても、今の仕様ではどうなっているのかを確認することが大切です。
今回の事象も、現在のAWS公式ドキュメントで確認できます。
ヘルスチェック猶予期間中であっても、Amazon EC2 Auto ScalingがインスタンスをEC2の running 状態ではないと検出した場合、そのインスタンスを即座に Unhealthy とマークして置き換える

つまり、Auto Scaling Group配下のEC2を停止するという行為は、今でも単体EC2の停止とは意味が違います。
単体EC2なら、停止はただの停止です。
しかしAuto Scaling Group配下では「本来動いているべきインスタンスが、正常な状態ではない」と判断される可能性があります。
これはAWSのバグというより、Auto Scalingが希望台数を維持するための仕様です。
問題は、作業者の意図とAuto Scalingの判断がずれることです。
HealthCheckとReplaceUnhealthyの違い
Auto Scalingには複数の内部プロセスがあります。今回特に関係するのがHealthCheckとReplaceUnhealthyです。
HealthCheckはインスタンスの正常性を確認し、ReplaceUnhealthyは、異常と判断されたインスタンスを置き換えるプロセスです。
AWS公式ドキュメントでは、以下のとおり説明されています。
・ReplaceUnhealthyを停止すると異常とマークされたインスタンスの置き換えは止まるが、EC2やELBのヘルスチェックに失敗したインスタンスは引き続き異常とマークされる
・ReplaceUnhealthyを再開すると、停止中に異常とマークされていたインスタンスが置き換えられる

つまり、ReplaceUnhealthyを止めていたとしても、その間にインスタンスが異常扱いになっていると、再開した瞬間に置き換えが走る可能性があります。
作業者としては「作業が終わったから戻そう」という感覚です。しかしAuto Scaling側では「このインスタンスはすでに異常とマークされています。プロセスが再開されたので置き換えます」という動きになる可能性があります。だから、単にプロセスを戻すのではなく、戻す前の状態確認が必要になります。
「ヘルスチェック猶予期間があるから大丈夫」ではない
ヘルスチェック猶予期間は、新しく起動したインスタンスがInServiceになってから、Auto Scalingがヘルスチェックの評価を始めるまでの待ち時間です(AWS公式ドキュメント)。
これだけを見ると「猶予期間を長くしておけば安全では?」と思うかもしれません。しかしここに落とし穴があります。
ヘルスチェック猶予期間は、アプリケーションの起動待ちには役立ちます。しかし、Auto Scaling Group内のインスタンスを停止した場合に、それを安全に見逃してくれる仕組みではありません。ここを勘違いすると危険です。
どう対策すべきか
対策として重要なのは、EC2を起動した直後にAuto Scalingのヘルスチェックや置き換えプロセスを機械的に戻さないことです。
「EC2起動後、5分待ってからヘルスチェックを有効化する」という運用は実務上よく見ます。ただし、5分という数字そのものが本質ではありません。本質は「Auto Scalingが正常と判断できる状態になってから戻す」ことです。

戻す前に確認すべきことは次のとおりです。
EC2のステータスチェックが正常であること
OSが正常に起動していること
ミドルウェアが起動していること
アプリケーションが正常応答していること
ELBまたはターゲットグループでHealthyになっていること
Auto Scaling Activityに異常な置き換え履歴がないこと
手順書には「起動後5分待つ」だけでなく、「何を確認できたら次の操作に進んでよいのか」を書く必要があります。
事前にどうチェックすべきか
このような事象を防ぐために、作業前に確認すべき点は大きく4つあります。
1. 対象EC2がAuto Scaling Group配下か確認する
EC2一覧だけを見ていると、普通のEC2に見えます。しかしタグやAuto Scaling Group名を見ると、ASG管理対象であることがあります。少なくとも以下を確認してください。
対象EC2はAuto Scaling Group配下か
Desired Capacityはいくつか
対象インスタンスを停止した場合、希望台数維持のために補充されるか
再作成された場合、元の状態を再現できるか
特に危険なのは、手作業で設定変更されたEC2がAuto Scalingで再作成されるケースです。再作成されたEC2は起動テンプレートやAMIに基づいて作られるため、手作業で入れた設定が消える可能性があります。
2. どのAuto Scalingプロセスを止めるべきか確認する
HealthCheckとReplaceUnhealthyは意味が違います。状況に応じて、どちらを止めるのか、Standbyを使うのかを判断する必要があります。スケジュールスケーリングやスケーリングポリシーの影響も確認してください。
プロセスの一時停止・再開:(AWS公式ドキュメント)
Standby機能:(AWS公式ドキュメント)
3. ヘルスチェック猶予期間と起動時間を確認する
EC2起動からステータスチェック正常化まで何分かかるか、アプリケーションが正常応答するまで何分かかるか、ELBがHealthyになるまで何分かかるか。これらがヘルスチェック猶予期間と整合しているかを確認してください。
4. 手順書に「戻し条件」を書く
運用手順書でよくあるのは、操作手順は書いてあるが戻し条件が曖昧なケースです。「EC2起動後、Auto Scalingのヘルスチェックを有効化する」だけでは危険です。上で挙げた確認項目をすべて満たしたことを確認してから戻す、と明記する必要があります。
運用手順で大事なのは操作そのものではありません。次の操作に進んでよい条件を明確にすることです。
これは運用設計の問題である
今回の話は、AWSのAuto Scalingという個別サービスの話に見えます。しかし実際には運用設計の問題です。
Auto Scalingを使うなら、設計時点で少なくとも以下を決めておく必要があります。
インスタンスを手動停止してよいのか
メンテナンス時はStandbyに入れるのか
HealthCheckやReplaceUnhealthyを一時停止するのか
どの条件を満たしたらAuto Scalingのプロセスを戻してよいのか
再作成された場合、設定やデータは失われないのか
手作業で変更した内容はAMI、起動テンプレート、IaCに反映されているのか
これらは、運用当日に作業者がその場で判断するものではありません。設計書、運用設計書、作業手順書、チェックリストに落としておくべき内容です。
クラウドでは、ひとつの操作に対して裏側で複数の自動化機能が反応します。作業対象のサーバだけを見ていると危険です。周辺にある自動制御の仕組みまで含めて、作業手順を考える必要があります。
これはバックアップ保存期限の設計と同じ構図です。「5日保存」と書いてあっても5営業日分なのか5世代なのかを確認しないと復旧時に認識違いが起きます。Auto Scalingも同様で、「EC2を停止・起動する」とだけ書くのではなく、その操作に対してAuto Scaling、ELB、CloudWatchがどう反応するのかまで設計しておく必要があります。
設計で決めるべきことを曖昧にしたまま運用に渡すと、作業時に現場が迷います。Auto Scalingの事故は、そのことを教えてくれる典型例です。
まとめ
Auto Scaling対象のEC2を停止・起動する場合、単体EC2と同じ感覚で作業してはいけません。
停止中にUnhealthyとマークされ、起動直後にプロセスを戻した瞬間に置き換えが走る。ヘルスチェック猶予期間を長くしても、それは防げない。「起動後5分待つ」は暫定ルールであって、設計ではない。
本質は、Auto Scalingが正常と判断できる状態になってから戻すことです。そしてその判断基準を、設計時点で手順書に落としておくことです。
クラウドの自動化は便利です。しかし、作業者の意図までは読んでくれません。だからこそ、設計では正常時の構成だけでなく、メンテナンス時・障害時・復旧時にシステムがどう振る舞うかまで考える必要があります。
この考え方については、以下の記事でも整理しています。
【前編】詳細設計で決めること|基本設計を「構築・テスト・運用できる形」に落とし込む工程
シリーズ全体は「実務で使えるシステム開発方法論」マガジンにまとめています。

コメント