この記事は、システム監視の基本を前編・後編に分けて解説するシリーズの前編です。
後編では、クラウド監視とFit & Gap、運用で使える監視設計について整理しています。
システム開発や基盤設計に関わっていると、「監視」という言葉は必ず出てきます。
「サーバは生きています。 `ping` は通っています」
そう報告した10分後に、業務が止まった。
原因は、Webサーバのプロセス停止だった。
サーバ自体にはネットワーク的に到達できていたため、 `ping` 監視では異常を検知できなかった。
答えは単純です。 `ping` が通ることと、システムが業務として使える状態であることは、まったく別の話だからです。
死活監視。リソース監視。ログ監視。プロセス監視。ジョブ監視。URL監視。SNMP監視。
言葉としては聞いたことがあっても、実際に「監視の仕組み」を説明しようとすると、意外と難しいものです。
若手SEの中には、監視を「サーバが落ちたらアラートが出る仕組み」「CPUやメモリが高くなったら通知する仕組み」「ログにエラーが出たらメールが飛ぶ仕組み」と理解している人もいます。
もちろん、間違いではありません。
ただし、それだけでは監視設計はできません。
監視では、何を監視するのか、どこから監視するのか、どの方式で監視するのか、どの条件で異常と判断するのか、誰に通知するのか、通知を受けた人が何を確認するのかまで決める必要があります。
監視とは、単にアラートを出す仕組みではありません。
システムの異常や異常予兆を、運用で対応できる形で検知する仕組みです。
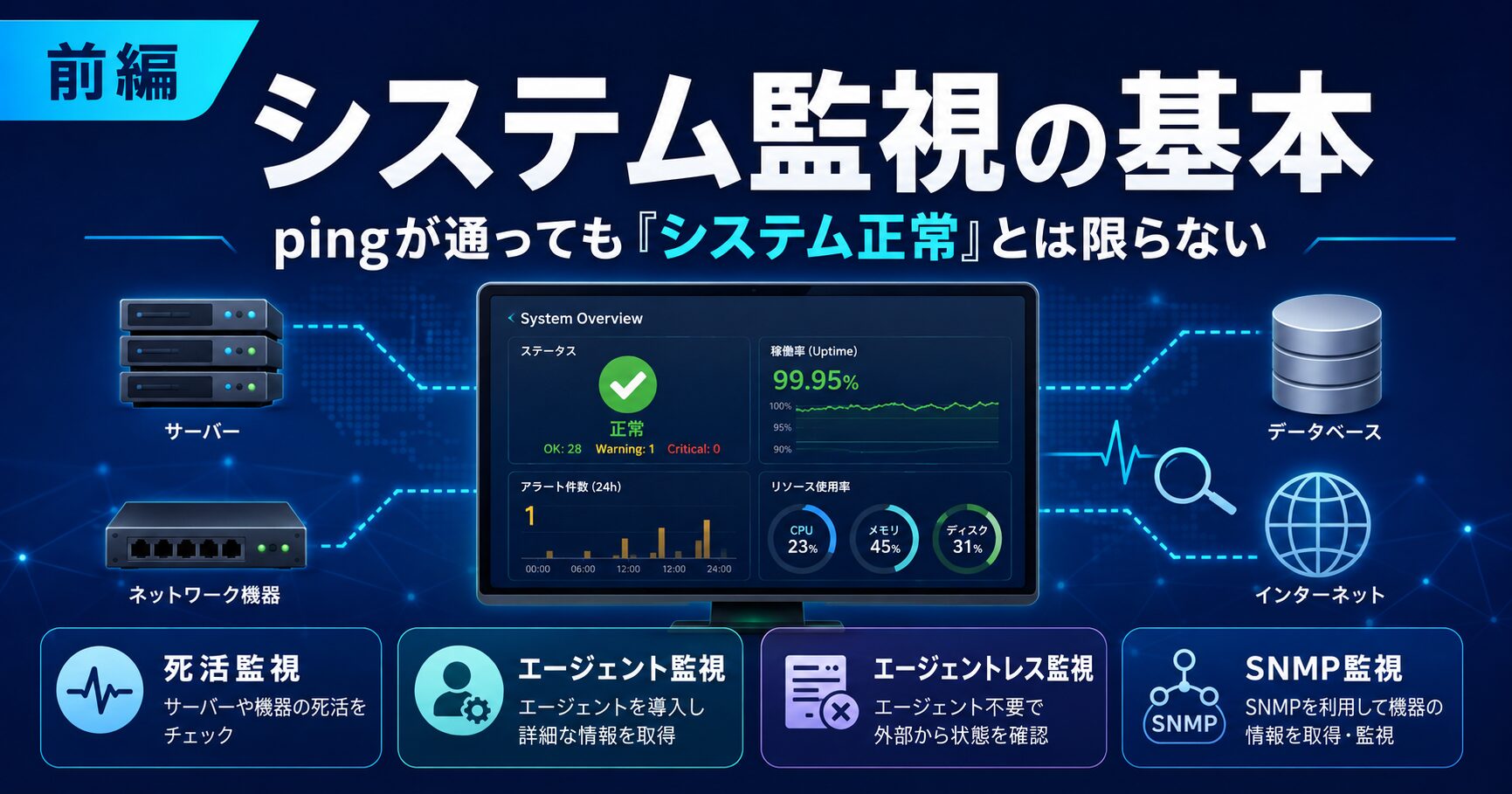
前編では、監視サーバー、監視対象サーバー、死活監視、エージェント監視、エージェントレス監視、SNMP監視、MIB/OIDの基本を整理します。
監視を「設定」ではなく「運用で使える仕組み」として理解するために、まずは基本構造から見ていきます。
システム監視とは何か
監視をしていなければ、障害が起きても運用側は気づけません。
利用者から「画面が開かない」と問い合わせが来て、初めて障害を認識する。これは運用の失敗です。
システムが正常に稼働しているか。障害の予兆がないか。それを運用で対応できる形で検知する仕組みです。
システム監視の目的は、大きく2つあります。
- システムが正常に稼働しているかを確認する
- システムに障害予兆となる兆候がないかを確認する
業務システムでは、障害そのものを完全にゼロにすることはできません。
だからこそ、障害が発生したときに早く気づく。
影響範囲を把握する。
一次対応につなげる。
必要に応じてエスカレーションする。
そのために監視があります。
監視には「監視する側」と「監視される側」がある
まず押さえるべき基本は、監視には「監視する側」と「監視される側」があるということです。
一般的なオンプレミスや仮想基盤の監視構成では、次のような役割があります。
- 監視サーバー
- 監視マネージャー
- 監視対象サーバー
- 監視エージェント
- 運用端末
- 通知先
監視サーバー、または監視マネージャーは、監視する側です。
監視対象サーバーは、監視される側です。
Webサーバ、APサーバ、DBサーバ、ジョブ管理サーバ、ストレージ、ネットワーク機器などが該当します。
監視サーバーは、監視対象に対して定期的に確認を行います。
たとえば、Web/APサーバとの通信状況、DBサーバのCPU負荷、共有ストレージのディスク容量、ログの異常メッセージなどを収集し、異常があれば運用者や管理者へ通知します。

ここで重要なのは、監視は「何となく全体を見ている」のではないということです。
監視対象ごとに、何を、どの方式で、どの周期で、どの閾値で、どの通知先へ送るかを細かく決めています。
前編では、まず代表的な監視方式として、死活監視、エージェント監視、エージェントレス監視、SNMP監視を整理します。

これらは、どれか1つだけを選ぶものではありません。
実際のシステムでは、複数の方式を組み合わせます。
たとえば、次のような組み合わせです。
- ネットワーク疎通は死活監視
- OS内部のCPU、メモリ、ディスクはエージェント監視
- ネットワーク機器やストレージはSNMP監視
- Webサービスの応答はURL監視
- クラウドリソースはCloudWatchやOCI Monitoring
- アプリケーションログはログ監視
- バッチ処理はジョブ監視
つまり、監視方式は「どれが正解か」ではありません。
そのシステムで何を知りたいのか。
どこまで異常を検知したいのか。
どのタイミングで誰が対応するのか。
これに応じて選びます。
死活監視とは何か
死活監視とは、監視対象が生きているかどうかを確認する監視です。
代表的には、監視サーバーから監視対象サーバーへ `ping` を実行し、応答があるかを確認します。
システム開発では、死活監視というと、まず `ping` による疎通確認をイメージすることが多いです。
`ping` は、監視サーバーから監視対象のIPアドレスへ到達できるか、相手が応答を返すかを確認するためによく使われます。
ここで注意が必要です。
`ping` が通ることは、システムが正常に動いていることを意味しません。
少しネットワークの階層で見ると、`ping` で確認しているのは、ざっくり言えばネットワーク層レベルの到達性です。
つまり、監視サーバーから監視対象のIPアドレスへ届き、相手が応答している、ということを確認しているに過ぎません。
その上で動いているWebサーバ、APサーバ、DB、ジョブ、業務アプリケーションまで正常であることを確認しているわけではありません。
たとえば、次のような状態でも `ping` は通ることがあります。
- Webサーバプロセスが停止している
- APサーバのスレッドが枯渇している
- DBリスナーが停止している
- DB表領域が枯渇している
- 業務APが内部エラーを返している
- ログイン画面は開くが検索処理が失敗する
- バッチジョブが異常終了している
- ディスク使用率が100%に近い
- メモリ不足で処理が極端に遅い

つまり、死活監視は重要ですが、それだけでは不十分です。
`ping` による死活監視で分かるのは、「ネットワーク的に到達できるか」「機器やOSが応答しているか」という入口の状態です。
一方で、業務として使える状態かどうかを確認するには、ポート監視、プロセス監視、URL監視、ログ監視、DB接続監視、ジョブ監視など、より上位の状態を見る監視が必要になります。
なお、死活監視は `ping` だけとは限りません。
SNMPを使って機器の稼働状態を確認する場合もあります。ネットワーク機器やストレージ、UPSなどでは、SNMPでインターフェース状態、電源状態、ファン、温度、装置状態などを取得したり、SNMP Trapで機器側から異常通知を受けたりします。
エージェント監視とは何か
エージェント監視とは、監視対象サーバーに監視用ソフトウェアを導入し、そのエージェントがサーバ内部の状態を収集する方式です。
監視対象サーバーの中に入って、CPU、メモリ、ディスク、プロセス、ログ、サービス状態などを確認するイメージです。

たとえば、次のような情報は、エージェントを入れた方が取得しやすくなります。
- CPU使用率
- メモリ使用率
- ディスク使用率
- ディスクI/O
- 特定プロセスの起動状態
- 特定サービスの状態
- OSログの特定メッセージ
- ミドルウェアログのエラー
- アプリケーションログの異常
- ファイル数やファイルサイズ
- 独自スクリプトの実行結果
商用監視製品であれば、JP1、Systemwalker、Hinemosなどが代表例です。
エージェント監視のメリットは、監視対象サーバーの内部情報を細かく取得できることです。
たとえば、単にDBサーバに `ping` が通るかだけでなく、DBプロセスが起動しているか、DB関連ログにエラーが出ていないか、CPUやメモリが逼迫していないか、といった情報を取得できます。
一方で、デメリットもあります。
エージェントをインストールする必要があります。
監視対象サーバーのリソースを使います。
バージョン管理が必要です。
OS更改やパッチ適用時に影響確認が必要です。
エージェント自体が停止すると監視できません。
セキュリティ上、導入や通信許可の調整が必要です。
そのため、エージェント監視を使う場合は、「何を監視したいからエージェントが必要なのか」を明確にします。
一方、エージェント監視のデメリットを見ると、「エージェントを入れずに済む方法はないか」という発想が生まれます。それがエージェントレス監視です。
エージェントレス監視とは何か
エージェントレス監視とは、監視対象サーバーに監視用エージェントを導入せず、監視サーバー側からリモートで状態を確認する方式です。たとえば、サーバに到達できるかを確認するだけなら `ping` で確認できます。
プロセス起動確認とWebサービス応答確認は違う
Webシステムでは、Apacheの `httpd` やTomcatのプロセスが起動していることを確認して、Web/APサーバが正常だと判断してしまうケースがあります。
しかし、プロセスが起動していることと、Webサービスが正常に応答していることは別です。
`httpd` が起動していても、アプリケーションのデプロイに失敗しているかもしれません。Tomcatが起動していても、DB接続でエラーになっているかもしれません。ロードバランサやリバースプロキシの経路が誤っていて、利用者から見ると画面に到達できないこともあります。
そのため、Webサービスの正常性を確認するには、HTTP/HTTPSで対象URLへアクセスし、HTTPステータスコードやレスポンス内容を確認することがあります。
たとえば、監視サーバーから `/healthcheck` や `/login` などのURLへHTTP GETリクエストを送り、HTTPステータスコードが `200` で返るか、レスポンス本文に想定した文字列が含まれるか、応答時間が閾値内かを確認します。
この考え方は、現在でもWebサービスの正常性確認として一般的に使われます。

ただし、最近のシステムでは、確認の粒度を分けることが増えています。
ロードバランサでは、配下のサーバへHTTP/HTTPSのヘルスチェックを行い、正常なターゲットだけにリクエストを振り分けます。
コンテナやKubernetes環境では、コンテナが生きているか、リクエストを受け付けられる状態か、起動完了しているかを分けて確認します。
また、より利用者目線で確認したい場合は、単一URLのGET確認だけでなく、外形監視やSynthetic Monitoringを使い、ログイン、検索、API呼び出しなど、実際の利用者操作に近いシナリオを定期実行することもあります。
つまり、`/healthcheck` や `/login` のHTTP応答確認は今でも有効です。
ただし、それだけで十分かは、システムの特性によります。
重要なのは、`httpd` やTomcatのプロセス起動確認だけで「Webサービスが正常」と判断しないことです。
Webサービスが業務として使えるかを確認するには、少なくともHTTP/HTTPSで実際にアクセスし、期待した応答が返ることを確認する必要があります。
ネットワーク機器やストレージの状態を確認する場合は、SNMPで情報を取得できることもあります。クラウドサービスであれば、APIやクラウド側のメトリクスから状態を取得できる場合もあります。
つまり、監視対象の内部にエージェントを入れなくても、監視サーバー側からリモートで確認できる内容であれば、エージェントレス監視を選択できます。
一方で、OSログの詳細確認、独自スクリプトの実行結果、アプリケーションログの細かな異常検知、サーバ内部の詳細なメトリクス取得などは、エージェントを入れた方が扱いやすい場合があります。
そのため、エージェントレス監視は「エージェントを入れなくて済むから楽」というだけではありません。
監視したい内容が外部から取得できるのか。
取得に必要な認証や権限をどう管理するのか。
通信経路やファイアウォール設定はどうするのか。
取得できる情報の粒度で運用判断できるのか。
ここまで考えたうえで、エージェント監視にするのか、エージェントレス監視にするのかを決めます。
代表的には、次のような方式があります。
- ping
- TCPポート監視
- HTTP/HTTPS監視
- SNMP監視
- SSH経由のコマンド実行
- Windows WMIによる情報取得
- APIによる状態取得
- クラウドサービスのメトリクス取得
エージェントレス監視のメリットは、監視対象サーバーにソフトウェアを導入しなくてもよいことです。
サーバ台数が多い場合、エージェント導入やバージョン管理の負荷を抑えられます。
また、ネットワーク機器、ストレージ、アプライアンス製品、クラウドサービス、マネージドサービスでは、そもそもエージェントを入れられないこともあります。
その場合は、SNMP、API、クラウドメトリクスなどを利用して監視します。
ただし、エージェントレス監視には制約があります。
外側から見える状態は分かるが、OS内部やアプリケーション内部の詳細までは見えないことがあります。
ログファイルの中身までは見にくいことがあります。
独自スクリプトの実行や詳細なメトリクス取得に制約が出ることがあります。
監視サーバーやネットワーク経路に障害があると、監視できないことがあります。
つまり、エージェントレス監視は「エージェントが不要だから簡単」という話ではありません。
エージェントを入れない代わりに、監視サーバー側の接続方式、認証、通信経路、権限、取得できるメトリクスの範囲を設計する必要があります。
SNMP監視とは何か
オンプレミスの監視やネットワーク機器監視でよく出てくるのが、SNMPです。
SNMPは、Simple Network Management Protocolの略です。
ネットワーク機器、サーバ、ストレージ、UPS、アプライアンスなどの状態を監視・管理するために使われるプロトコルです。SNMPの管理情報を扱うMIBについては、RFC 3418でもSNMPエンティティの動作を説明する管理オブジェクトとして定義されています。(IETF Datatracker)
SNMP監視では、一般的に次のような役割があります。
- SNMPマネージャー
- SNMPエージェント
- MIB
- OID
- SNMP Get
- SNMP Trap

SNMPマネージャーは、監視する側です。
SNMPエージェントは、監視される機器側で動作し、機器の状態情報を持っています。
SNMP Getは、マネージャーがエージェントに対して「この情報を教えて」と問い合わせる方式です。
SNMP Trapは、機器側からマネージャーへ「異常が起きた」と通知する方式です。
たとえば、ネットワーク機器でインターフェースがDownした場合、機器側からSNMP Trapが飛ぶことがあります。
監視サーバーはそのTrapを受け取り、アラートとして運用者へ通知します。
SNMP監視でつまずきやすいOIDとMIB
SNMPの説明では、OIDやMIBという言葉が当たり前のように出てきます。
しかし、これを正しく理解していないと、
「MIBファイルを監視製品に読み込ませれば、監視できるんですよね」
という誤解につながります。
これは危険です。
まず、OIDから整理します。
OIDは、Object Identifierの略です。
一言でいえば、監視対象機器の中にあるデータの住所です。
ネットワーク機器やサーバは、人間が話すように「CPU使用率を教えてください」と理解してくれるわけではありません。
SNMPでは、監視マネージャーが、監視対象機器に対して、
「この番号の情報をください」
と問い合わせます。
たとえば、あるネットワーク機器のCPU使用率を表すOIDが、次のような番号だったとします。
1.3.6.1.4.1.9.9.109.1.1.1.1.5copy
監視マネージャーは、このOIDを指定して、監視対象機器に問い合わせます。
すると、機器側のSNMPエージェントは、
80copy
のように値を返します。
この場合、人間から見ると「CPU使用率が80%」という意味です。
しかし、機器や監視マネージャーのやり取りとしては、基本的には「どのOIDの値を取るか」という話になります。
つまり、OIDは、監視対象機器の中にある監視項目の住所です。
次にMIBです。
MIBは、Management Information Baseの略です。
一言でいえば、OIDという数字の住所と、人間が理解できる意味を対応づける辞書です。

人間が、毎回、
1.3.6.1.4.1.9.9.109.1.1.1.1.5copy
という数字を見ても、それが何を意味するのかは分かりません。
そこで、ベンダーが提供するMIBファイルを使います。
MIBには、たとえば次のような対応関係が定義されています。
1.3.6.1.4.1.9.9.109.1.1.1.1.5
=
CPUの5分平均使用率copy
実際には、製品ごとの正式な項目名や階層構造で定義されていますが、考え方としてはこのようなものです。
つまり、OIDは「住所」です。
MIBは「住所録」または「辞書」です。
OIDが分かれば、監視マネージャーは対象機器から値を取得できます。
MIBがあれば、そのOIDが何を意味するのかを人間が理解しやすくなります。
ここまでは、SNMP監視の基本です。
ただし、実務で本当に重要なのはここからです。
MIBを登録しただけでは監視設計は終わらない
MIBファイルを監視製品に読み込ませると、製品固有のOIDやTrapの意味を解釈できるようになります。
しかし、それだけでは監視設計は終わりません。
MIBは、あくまで辞書です。
辞書を入れただけでは、
- どのOIDを監視するのか
- どの値を警告とするのか
- どの値を異常とするのか
- どのTrapを通知対象にするのか
- どのTrapは通知しないのか
- 何分継続したら異常にするのか
- 誰に通知するのか
- 通知を受けた人が何を確認するのか
は決まりません。
ここを決めるのが監視設計です。
たとえば、CPU使用率のOIDを監視するとします。
CPU使用率が80%になったら、必ず異常でしょうか。
そうとは限りません。
夜間バッチの時間帯だけ一時的にCPUが上がるシステムもあります。
バックアップ処理中だけCPUやI/Oが上がることもあります。
短時間のスパイクであれば、業務影響がない場合もあります。
一方で、CPU使用率が70%程度でも、長時間継続すれば性能劣化の予兆かもしれません。
つまり、単に「CPU使用率のOIDを監視する」だけでは不十分です。
次のように、運用で判断できる条件まで落とす必要があります。
CPU使用率が90%以上
かつ
5分以上継続した場合は警告
CPU使用率が95%以上
かつ
10分以上継続した場合は異常
ただし、夜間バッチ時間帯は別閾値とするcopy
もちろん、これは例です。
実際の閾値は、システムの特性、性能要件、通常時の負荷、ピーク時間帯、バッチ処理、運用体制に応じて決めます。
MIBを入れただけで監視を始めると何が起きるか
よくない進め方は、ベンダーのMIBファイルを監視サーバーに登録し、デフォルト設定に近い形で対象機器の監視を一斉に始めてしまうことです。
この場合、運用開始後にアラートが大量に出ることがあります。
いわゆる、アラートの大洪水です。
なぜそうなるのか。
主な理由は3つあります。
1つ目は、通知すべきイベントと、通知しなくてよいイベントを分けていないことです。
機器や製品は、さまざまなTrapや状態変化を出します。
その中には、本当に即時対応が必要な障害もあります。
一方で、単なる情報通知、状態変化、復旧通知、一時的な警告、運用上は無視してよいメッセージもあります。
これらをすべて同じように通知すると、運用者は大量のアラートを受けることになります。
2つ目は、閾値や継続時間をシステム特性に合わせていないことです。
CPU、メモリ、ディスクI/O、ネットワーク使用率などは、システムによって通常値が違います。
業務ピーク時にCPUが高くなるシステムもあります。
夜間バッチ中にI/Oが急増するシステムもあります。
月次処理の日だけ負荷が上がるシステムもあります。
それを考慮せず、一般的な閾値だけで監視すると、正常な業務処理まで異常として検知してしまいます。
3つ目は、テスト工程で実際のログやアラートを精査していないことです。
監視条件は、設計時点の机上検討だけでは決めきれません。
特に、ログ監視やTrap監視は、実際にシステムを動かしてみないと、どのメッセージがどれくらい出るのか分からないことがあります。
システムテスト、運用テスト、本番リハーサルで、業務データ、日次処理、月次処理、ピーク時のトランザクション、バックアップ、ジョブ、外部連携などを動かして初めて、大量のログやイベントが出てきます。
その中から、
- 本当に通知すべきもの
- 通知は不要だが記録しておくもの
- 除外してよいもの
- 閾値や継続時間を見直すべきもの
- 一次対応手順に落とすべきもの
を精査する必要があります。
これをやらずに本番稼働すると、運用開始後に大量のアラートが出ます。
すると、運用者はアラートを見切れなくなります。
最悪なのは、本当に重要な障害が、不要なアラートの中に埋もれてしまうことです。
監視は、アラートをたくさん出せばよいわけではありません。
運用者が判断できる形で、必要な異常を検知することが重要です。
SNMP監視も詳細設計の対象である
ここまで見ると分かるように、SNMP監視は単にMIBを登録する作業ではありません。
MIBを登録する。
OIDを選ぶ。
Trapを受ける。
閾値を決める。
重大度を決める。
通知先を決める。
除外条件を決める。
テスト工程で実際の発報状況を確認する。
運用手順と対応づける。
ここまで含めて、SNMP監視も詳細設計の中で決めるべき重要な領域です。
前編のまとめ|監視の基本構造を押さえる
監視には「監視する側」と「監視される側」がある
監視サーバーが監視対象であるWeb/AP/DBサーバ、ネットワーク機器などに対して、定期的に状態を確認する構造が基本です。
`ping` が通ることと、システムが業務として使えることは別である
死活監視は、あくまでネットワーク的な到達性の確認です。プロセス、DB、アプリケーションまで正常かどうかは、別の監視で確認する必要があります。
監視方式は、監視したい内容に応じて組み合わせる
死活監視、エージェント監視、エージェントレス監視、SNMP監視は、どれか一つを選ぶものではありません。監視したい内容に応じて組み合わせます。
MIBを登録しただけでは監視設計は終わらない
OIDの選定、閾値、継続時間、通知先、除外条件まで決めて初めて、運用で使える監視になります。
アラートは多ければよいわけではない
閾値やシステム特性を考慮せず監視を始めると、アラートの大洪水が起きます。テスト工程で実際の発報内容を精査することが必要です。
監視は、製品を入れて設定するだけの作業ではありません。
監視対象、監視方式、閾値、検知条件、除外条件、重大度、通知先、一次対応手順まで決める設計作業です。
後編では、クラウド監視に進みます。
AWS CloudWatchやOCI Monitoringを使えば、自前の監視サーバーが不要になることもあります。
ただし、「クラウド監視サービスを使えば、監視設計が楽になる」は半分正解で半分誤解です。
クラウドでも、何を監視するか。どの値を異常とするか。誰に通知するか。一次対応をどうするか。これらは自分たちで決める必要があります。
むしろ、オンプレと違い「気づかないうちにコストが膨らむ」という、クラウド固有のリスクも監視の対象になります。
後編では、AWS CloudWatchやOCI Monitoringなどのクラウド監視、オンプレミスからクラウド移行時の監視Fit & Gap、監視設計で決めるべき項目を整理しています。
あわせて読みたい

コメント